General#
Introduction#
The SoundScape Renderer (SSR) is a software framework for real-time spatial audio reproduction running under GNU/Linux, macOS and possibly some other UNIX variants. The MS Windows standalone version is experimental. The SSR renderers are available as externals for Pure Data for all operating systems. Refer to SSR in Pure Data.
The current implementation provides:
There is also the slightly exotic Generic Renderer, which is essentially a MIMO convolution engine. For each rendering algorithm, there is a separate executable file.
The SSR is intended as versatile framework for the state-of-the-art implementation of various spatial audio reproduction techniques. You may use it for your own academic research, teaching or demonstration activities or whatever else you like. However, it would be nice if you would mention the use of the SSR by e.g. referencing [Geier2008a] or [Geier2012].
Note that so far, the SSR only supports two-dimensional reproduction for most renderers (the binaural renderer with SOFA files being the laudable exception that already supports 3D). For WFS principally any convex loudspeaker setup (e.g. circles, rectangles) can be used. The loudspeakers should be densely spaced. For VBAP circular setups are highly recommended. APA does require circular setups. The binaural renderer can handle only one listener at a time.
Matthias Geier, Jens Ahrens, and Sascha Spors. The SoundScape Renderer: A unified spatial audio reproduction framework for arbitrary rendering methods. In 124th AES Convention, Amsterdam, The Netherlands, May 2008 Audio Engineering Society (AES).
Matthias Geier and Sascha Spors. Spatial audio reproduction with the SoundScape Renderer. In 27th Tonmeistertagung – VDT International Convention, 2012.
Quick Start#
After downloading the SSR package from http://spatialaudio.net/ssr/download/, open a shell and use following commands:
tar xvzf ssr-x.y.z.tar.gz
cd ssr-x.y.z
./configure
make
sudo make install
qjackctl &
ssr-binaural my_audio_file.wav
You have to replace x.y.z with the current version number,
e.g. 0.5.0. With above commands you are performing the following
steps:
Unpack the downloaded tarball containing the source-code.
Go to the extracted directory [1].
Configure the SSR.
Build the SSR.
Install the SSR.
Open the graphical user interface for JACK (
qjackctl). Please click “Start” to start the server. As alternative you can start JACK with:jackd -d alsa -r 44100
See section Running the SSR and
man jackdfor further options.Open the SSR with an audio file of your choice. This can be a multichannel file.
This will load the audio file my_audio_file.wav and create a virtual
sound source for each channel in the audio file.
Please use headphones to listen to the output generated by the binaural renderer!
If you want to use a different renderer, use
ssr-brs,
ssr-wfs,
ssr-vbap,
ssr-aap,
ssr-dca or
ssr-generic
instead of ssr-binaural.
If you don’t need a graphical user interface and you want to dedicate all your resources to audio processing, try:
ssr-binaural --no-gui my_audio_file.wav
For further options, see the section Running the SSR and
ssr-binaural --help.
Audio Scenes#
Format#
The SSR can open .asd files – refer to the section Audio Scene Description Format (ASDF) – as well as
normal audio files. If an audio file is opened, SSR creates an
individual virtual sound source for each channel which the audio file
contains. If a two-channel audio file is opened, the resulting virtual
sound sources are positioned like a virtual stereo loudspeaker setup
with respect to the location of the reference point. For audio files
with more (or less) channels, SSR randomly arranges the resulting
virtual sound sources. All types that ecasound and libsndfile can open
can be used. In particular this includes .wav, .aiff, .flac
and .ogg files.
In the case of a scene being loaded from an .asd file, all audio
files which are associated to virtual sound sources are replayed in
parallel and replaying starts at the beginning of the scene.
Coordinate System#
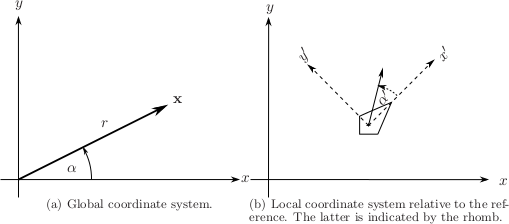
The coordinate system used in the SSR. In ASDF \(\alpha\) and \(\alpha'\) are referred to as azimuth – refer to the section Audio Scene Description Format (ASDF).#
Fig. 1.1 (a) depicts the global coordinate system used in the SSR. Virtual sound sources as well as the reference are positioned and orientated with respect to this coordinate system. For loudspeakers, positioning is a bit more tricky since it is done with respect to a local coordinate system determined by the reference. Refer to Fig. 1.1 (b). The loudspeakers are positioned with respect to the primed coordinates (\(x'\), \(y'\), etc.).
The motivation to do it like this is to have a means to virtually move the entire loudspeaker setup inside a scene by simply moving the reference. This enables arbitrary movement of the listener in a scene independent of the physical setup of the reproduction system.
Please do not confuse the origin of the coordinate system with the reference. The coordinate system is static and specifies absolute positions.
The reference is movable and is always taken with respect to the current reproduction setup. The loudspeaker-based methods do not consider the orientation of the reference point but its location influences the way loudspeakers are driven. E.g., the reference location corresponds to the sweet spot in VBAP. It is therefore advisable to put the reference point to your preferred listening position. In the binaural methods the reference point represents the listener and indicates the position and orientation of the latter. It is therefore essential to set it properly in this case.
Note that the reference position and orientation can of course be updated in real-time. For the loudspeaker-based methods this is only useful to a limited extent unless you want to move inside the scene. However, for the binaural methods it is essential that both the reference position and orientation (i.e. the listener’s position and orientation) are tracked and updated in real-time. Refer also to Sec. Head-Tracking.
Audio Scene Description Format (ASDF)#
Besides pure audio files, SSR can also read the Audio Scene Description Format (ASDF) Currently, two versions of the ASDF are supported.
There is a legacy version of the ASDF [Geier2008b], which has been supported since the beginning, but which can only describe static scenes. Recently, support for a new version 0.4 of the format was added, which allows creating scenes with moving sound sources. Detailed documentation is available at https://AudioSceneDescriptionFormat.readthedocs.io/.
The XML syntax between the two versions is not compatible.
The new version is only used when version 0.4 is specified like this:
<asdf version="0.4">
The rest of this section describes the legacy version of the ASDF.
As you can see in the example audio scene below, an audio file can be assigned to each virtual sound source. The replay of all involved audio files is synchronized to the replay of the entire scene. That means all audio files start at the beginning of the sound scene. If you fast forward or rewind the scene, all audio files fast forward or rewind. Note that it is significantly more efficient to read data from an interleaved multichannel file compared to reading all channels from individual files.
Matthias Geier, Jens Ahrens, and Sascha Spors. ASDF: Ein XML Format zur Beschreibung von virtuellen 3D-Audioszenen. In 34rd German Annual Conference on Acoustics (DAGA), Dresden, Germany, March 2008.
Legacy Syntax#
The format syntax is quite self-explanatory. See the examples below.
Note that the paths to the audio files can be either absolute (not
recommended) or relative to the directory where the scene file is
stored. The exact format description of the ASDF can be found in the XML
Schema file asdf.xsd.
Find below a sample scene description:
<?xml version="1.0"?>
<asdf version="0.1">
<header>
<name>Simple Example Scene</name>
</header>
<scene_setup>
<source name="Vocals" model="point">
<file>audio/demo.wav</file>
<position x="-2" y="2"/>
</source>
<source name="Ambience" model="plane">
<file channel="2">audio/demo.wav</file>
<position x="2" y="2"/>
</source>
</scene_setup>
</asdf>
The input channels of a soundcard can be used by specifying the channel
number instead of an audio file, e.g. <port>3</port> instead of
<file>my_audio.wav</file>.
Examples#
We provide an audio scene example in ASDF with this release. You find it
in data/scenes/live_input.asd. If you load this file into the
SSR it will create 4 sound sources which will be connected to the first four
channels of your sound card. If your sound card happens to have less
than four outputs, less sources will be created accordingly. More
examples for audio scenes can be downloaded from the SSR website
http://spatialaudio.net/ssr/.
IP Interface#
One of the key features of the SSR is the ability to remotely control it via a network interface. This enables you to straightforwardly connect any type of interaction tool from any type of operating system. There are multiple network interfaces available, see Network Interfaces.
Bug Reports, Feature Requests and Comments#
Please report any bugs, feature requests and comments at
https://github.com/SoundScapeRenderer/ssr/issues or send an e-mail to
ssr@spatialaudio.net. We will keep
track of them and will try to fix them in a reasonable time. The more
bugs you report the more we can fix. Of course, you are welcome to
provide bug fixes.
Contributors#
- Written by:
Matthias Geier, Jens Ahrens
- Scientific supervision:
Sascha Spors
- Contributions by:
Peter Bartz, Hannes Helmholz, Florian Hinterleitner, Torben Hohn, Christoph Hohnerlein, Christoph Hold, Lukas Kaser, André Möhl, Till Rettberg, David Runge, Fiete Winter, IOhannes m zmölnig
- GUI design:
Katharina Bredies, Jonas Loh, Jens Ahrens
- Logo design:
Fabian Hemmert
See also the Github repository https://github.com/soundscaperenderer/ssr for more contributors.
Your Own Contributions#
The SSR is thought to provide a state of the art implementation of
various spatial audio reproduction techniques. We therefore would like
to encourage you to contribute to this project since we can not assure
to be at the state of the art at all times ourselves. Everybody is
welcome to contribute to the development of the SSR. However, if you are
planning to do so, we kindly ask you to contact us beforehand (e.g. via
ssr@spatialaudio.net).
The SSR is in a rather temporary state and we might apply some
changes to its architecture. We would like to ensure that your own
implementations stay compatible with future versions.