Use Cases#
SSR in Pure Data#
The SSR renderers are available as externals in Pure Data (Pd). Install them in Pd via , then search for ‘ssr’. This is available on both Linux and macOS, whereby the macOS version for Macs with Apple silicon is experimental. If this one does not work for you, use Pd for Intel processors with Rosetta.
Each renderer is available as a separate external, namely
ssr_binaural~, ssr_brs~, ssr_dca~,
ssr_aap~, ssr_wfs~ and ssr_vbap~.
The externals have to be added to Pure Data’s path,
for example by creating an object [declare -path ssr] in your patch.
Here is a screenshot of what it looks like when using SSR’s binaural renderer with the minimum-phase EQ’d HRIRs of the FABIAN manikin and 2 virtual sound sources in Pd, whereby the signal that feeds source 1 is a sine of 440 Hz, and the signal that feeds source 2 is noise:
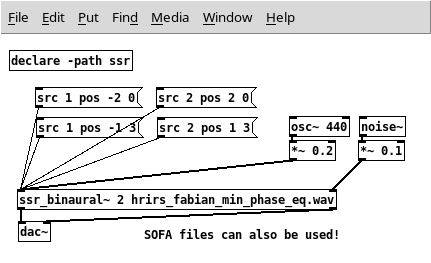
The source positions, orientations and many other things can be changed by sending messages to the external. See the help patch for all available messages.
The computational performance of SSR in Pd is somewhat lower than that of the standalone version because we have not got it to work in Pd with internal block sizes that are larger than 64. Such short blocks cause filters to be cut in very large numbers of partitions, which produces computational overhead.
Using SSR for Listening Experiments#
This is one of the main applications for which we use SSR. Most of the times, we perform the experiment over headphones. We use the BRS renderer in which each condition of the experiment is represented by a virtual source. The impulse responses that are associated to that source implement the actual experimental condition. Lastly, we use external software like Python or MATLAB to have a GUI for the subjects and to play audio that we route to SSR via JACK. Switching from one condition to another one is implemented by muting an unmuting the corresponding virtual sources in SSR through the network interface.
Watch this 1m:35s video to see this in action: https://youtu.be/aaAc7cDlacU
All resources for the subsequent subsections are found here: https://github.com/SoundScapeRenderer/listening-test
Using SSR for General Realtime Multichannel Signal Processing#
SSR is designed for providing the spatial audio rendering functionality as discussed throughout this documentation. Looking at the entire concept from a different angle enables a large set of applications that are not obvious at first sight. One application that we would like to discuss here with some amount of comprehensiveness is dynamic or “realtime” multichannel signal processing. More precisely, we will demonstrate how SSR allows for performing multichannel realtime convolution whereby we can exchange the filters that are being applied.
1-in-1-out#
Let’s assume that we want to filter a single-channel signal in realtime with a filter that we would like to be able to replace as the convolution is going. We use the Binaural Renderer for this with one virtual source.
SSR accepts one input channel, which it convolves with two different dedicated
impulse responses (one for the left and one for right ear) to produce two output
signals. We would like to process only one channel so that we simply ignore the
second output. The file
data_linked_in_ssr_manual/impulse_responses/irs_1-in-1-out.wav
that contains the pre-computed impulse responses that we would like to filter
with looks as follows:
1st channel: impulse response of the filter that will be invoked by calling the index
02nd channel: only zeros (we don’t want it to produce output)
3rd channel: impulse response of the filter that will be invoked by calling the index
3594th channel: only zeros (we don’t want it to produce output)
…
719th channel: impulse response of the filter that will be invoked by calling the index
1720th channel: only zeros (we don’t want it to produce output)
(The indexing is a bit funny because we’re using the binaural render for convenience. In real-life, you would most likely use the BRS renderer with which the indexing is 0, 1, 2, …, 359 instead of the 0, 359, 358, …, 1 that it is here.)
You have probably gotten the idea already. We can use this setup for 1-in-1-out
dynamic filtering by not interpreting the loaded filter as ear impulse responses
that are called via given orientation angles of the user. Rather, we think of
filter indices that we can call using the head tracking interface. We only need
to replace the head tracking with another interface that allows us to select the
desired filter indices. Here is a Pd patch that does exactly this:
data_linked_in_ssr_manual/select_filter_by_index.pd
Start the SSR using:
ssr-binaural --fudi-server=1147 --hrirs=data/scenes/impulse_responses/irs_1-in-1-out.wav
and drag and drop an audio file into the GUI.
Start Pd with the control patch and play around with the filter index. You will find that, depending on the chosen filter index, different amounts of lowpass filtering will be applied in this example.
Multiple Input Multiple Output#
Let’s increase the complexity by a considerable amount and perform 2-in-8-out as an example for multiple input multiple output (MIMO) dynamic convolution. We used this in the experiment in [Ma2019] to create a user-tracked 8-channel loudspeaker array (8 outs) that delivers binaural content (2 ins) by means of crosstalk cancelation. We are actually dealing with two 1-in-8-out systems (one for the left ear content and one for the right ear content) the outputs of which are added.
The user was able to be located at any possible position along a straight line of length 80 cm that was parallel to the loudspeaker array. We used a tracking system to monitor the instantaneous position.
Here is how we implemented it:
We used the BRS renderer for the implementation. It has two outputs, which means that we need 4 SSR running in parallel.
Each BRS renderer employed a scene with 2 virtual sound sources.
SSR 1: Virtual source 1 produced the output signal for the left ear content for loudspeakers 1 and 2; virtual source 2 produced the output signal for the right ear content for loudspeakers 1 and 2
SSR 2: Same like SSR 1 but for loudspeaker 3 and 4
SSR 3 and 4 drive loudspeakers 5 and 6 as well as 7 and 8, respectively.
Each combination of input and output allows for applying 360 different impulse responses the indices of which we can select using the head tracking interface. This means that we were required to quantize the user’s position to 360 different positions along that 80-cm-long-line which effectively reduced the head tracking accuracy to 0.8/359 m = 2 mm. We precomputed all impulse responses for all combinations of input and output channel and user position in MATLAB.
The last component that remains to be implemented is a patch that transforms
user position to filter index and distributes that to all SSR synchronously. We
did this with this Pd patch:
data_linked_in_ssr_manual/tracker_to_4_ssr.pd. You will see that
there is no mechanism for guaranteeing that all filter indices
arrive synchronously. We rather send updates as soon as they come in from the
tracker. The last index that an SSR instance receives just before the processing
of a new signal block is the index that SSR uses. We did not notice a single
occasion when this led to audible consequences because of a lack of
synchronicity.
When running several SSR at a time, we need to make sure that they all use different JACK client names as well as that all SSR instances receive TCP/IP messages on different ports. SSR will otherwise refuse to start.
Here is a shell script that work on both Linux and macOS is SSR is installed:
data_linked_in_ssr_manual/start_ssr_4_times.sh (and here one
for the macOS app:
data_linked_in_ssr_manual/start_ssr_4_times_macos_app.sh, make
them executable using chmod a+x SCRIPT_NAME.SH, in the macOS script,
you need to adapt the global paths to the asdf files) that starts the 4 SSR
instances for the 8-channel crosstalk-canceling array. It then waits 5 s to
make sure that all SSR instances have started up and then performs the
required JACK connections. Note the --input-prefix=XXX:XXX and
--output-prefix=YYY:YYY arguments. These make sure that SSR does not
automatically connect to existing JACK ports. We did this for convenience to
have manual control over which connections are established. All SSR instances
would otherwise connect to output channels 1 and 2 automatically.
Afterwards, start Pd with the patch referenced above.
The audio signal was played from a GUI via JACK like we did it with other listening experiments.
Note that you will need an audio interface with at least 8 output channels for all of the above to work. You will otherwise receive error messages about failure to establish some of the JACK connections.
X. Ma, C. Hohnerlein, J. Ahrens. Concept and Perceptual Validation of Listener-Position Adaptive Superdirective Crosstalk Cancelation Using a Linear Loudspeaker Array. JAES 67(11), p. 871-881, 2019, DOI: 10.17743/jaes.2019.0037